1. 개요
- 기간 : 2023.4.7 ~ 4.12 (총 6일)
- 과제 : 직접 선택한 데이터셋을 사용해 머신러닝 예측 모델 구축, 성능 평가 및 인사이트 공유
- 코드 보러가기
GitHub - HeeYoung-code/Codestates-Project
Contribute to HeeYoung-code/Codestates-Project development by creating an account on GitHub.
github.com
section2 project
신용카드 고객 연체 예측 모델 ▲▲은행 데이터팀 박희영
docs.google.com
1-1. 문제 정의

내가 선택한 문제는 다음과 같다.
온라인 전문 ▲▲은행에서는 최근 공격적 마케팅 성공으로 신용카드 고객 다수 확보했다. 하지만 사용 승인 남발로 인한 연체율이 상승하는 부작용을 낳았다. 이러한 문제를 해결하기 위해 데이터팀에서는 ‘다음달 신용카드 대금 연체 위험도’ 예측 모델을 만들어 고객관리팀과 마케팅팀으로 전달하려고 한다. 해당 부서들은 전달 받은 고객군에 따른 맞춤 관리를 하기로 했다.
1-2. 데이터
- 대상 : 고객 26000여명
- 사용 특성 (Feature) : 성별, 자동차 소유, 부동산 소유, 총 수입, 자금 출처, 최종 학력, 자녀 수, 가족 구성, 가족 수, 주택 종류, 고용 기간, 나이, 연락수단 수, 직업, 등록 기간 등
- 예측 대상 (Label) : 고객 신용도
(데이터 출처 : kaggle.com)

- 타겟 클래스 : 3개 (숫자가 낮을수록 신용도가 낮아 강도 높은 관리가 필요하다)
| 예측 대상 분류 | 개요 및 필요 조치 | |
| Class 0 |
|
|
| Class 1 |
|
|
| Class 2 |
|
|
2. 데이터 정제
- 결측치 및 중복치 삭제
- 이상치 삭제
- Feature Engineering
- 나이, 고용기간 표기 : 날짜 기준에서 연차 기준으로 수정
- 핸드폰, 이메일 등 연락수단 정보를 합쳐 ‘등록 연락수단 수’로 수정
3. 모델 선정
- 사용 모델 : Logistic 회귀, KNN, NaveBayes, DecisionTree, RancomForest, XGBoost
- Accuracy가 가장 높은 RandomForest와 XGB 선정

3-1 Class Imbalance 해결 후 모델 최종 선정

- 위 그래프는 훈련 데이터셋의 예측 타겟의 클래스 분포
- 클래스 불균형으로 모델 정확도가 낮다고 판단
- Random Over Sampler를 이용해 클래스 분포를 비슷하게 맞춘 후 RandomForest, XGB 모델 재학습
- 결과(정확도) : RandomForest - 0.68 / XGB - 0.6
- RandomForest로 모델 최종 선정
4. 모델 성능 향상
4-1. 하이퍼파라미터 튜닝

- 직접 튜닝 방식
- 3번의 실험을 거쳤고 실험1의 튜닝법 선택
- 튜닝 결과 정확도 미세 상승
4-2 Pemutation Importance

- 각 특성별로 모델 결과에 미치는 영향 확인
- 음수(-)의 영향을 갖는 특성 6개 발견
- 음수를 영향을 주는 것보다 없는 것이 낫다는 판단 하에 '음수 특성' 삭제 후 재학습
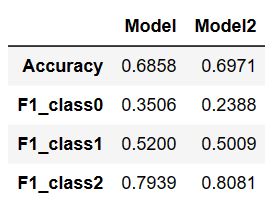
- 아래와 같이 정확도 소폭 증가
5. 모델 적용 기대효과
- 고객 분류를 통한 효과적 마케팅
- 연체 위험군 집중 관리로 연체율 하락 기대
- 연체율 관리로 고객 서비스 및 유지
- 연체 방지로 카드·대출 등 다른 금융 상품 잠재적 고객 확보
6. 개선 방향
- 클래스 불균형 문제를 해결한 후에도 여전히 '클래스0' 예측 성능이 떨어진다. 이 문제를 해결할 수 있는 적극적 방법 모색.
- 모델 Accuracy가 개선되긴 했지만 실무에 투입하기엔 여전히 낮은 편. 데이터 정제, 모델 선정, 클래스 불균형 등 전반의 과정을 다시 진행해야.
'My Project' 카테고리의 다른 글
| [코드스테이츠 / Flask] 머신러닝 모델을 웹서비스로 구현하기 (0) | 2023.06.26 |
|---|---|
| [코드스테이츠 / 딥러닝] 도배 하자 이미지 분류 (ResNet, EfficientNet) (0) | 2023.05.26 |
| [코드스테이츠 / 데이터 분석] 다음 분기에 어떤 게임을 기획할까? (0) | 2023.05.26 |


